CVE-2023–24329 Bypassing URL Blackslisting using Blank in Python urllib library

Summary
in-depth analysis of CVE-2023–24329
Description
CVE: CVE-2023–24329
Description: An issue in the urllib.parse component of Python before 3.11.4 allows attackers to bypass blocklisting methods by supplying a URL that starts with blank characters.
Vendor: Python Software Foundation
Version: => 3.11.3

Background Story
Python is the most popular programming language in the world. The exploit of CVE-2023–24329 is pretty easy, but its impact is
significant because the urllib.parse library is used in many web applications to prevent blacklisting attacks, such as
injection and file upload. When this library is broken, attackers can manipulate inputs and bypass filters
the bug affects any version before 3.11.4 , I'm using python3 3.11.3 version which is the last version before the patch
Reproducing the Vulnerability
urllib.parse breaks the URL (A Uniform Resource Locator) strings up in components such as the schema (file, FTP, HTTP, HTTP)
that’s used in the URL so when parsing a URL with URL as the example.com

[1] in normal case urlparse function detects the schema of the provided URL and this is used to prevent LFI (file)
[2] if the user adds space to the function will focus to detect the scheme which considers the URL schema with space as below
Demo of the Exploitation scenario
I made a simple web app to Demonstrate the exploit of this CVE in case the library is used to prevent LFI (Local File
Inclusion) using the Flask library which easily can be installed by pip3 install flask with urllib with two files app.py and
index.html
- app.py
from flask import Flask, render_template, request
import urllib.request
import urllib.error
app = Flask(__name__)
def safeURLOpener(inputLink):
block_schemes = ["file", "gopher", "expect", "php", "dict", "ftp", "glob", "data"]
block_host = ["instagram.com", "youtube.com", "tiktok.com"]
input_scheme = urllib.parse.urlparse(inputLink).scheme
input_hostname = urllib.parse.urlparse(inputLink).hostname
if input_scheme in block_schemes:
return "Input scheme is forbidden"
if input_hostname in block_host:
return "Input hostname is forbidden"
try:
target = urllib.request.urlopen(inputLink)
content = target.read().decode('utf-8')
return content
except urllib.error.URLError as e:
return "Error opening URL: " + str(e)
@app.route('/', methods=['GET', 'POST'])
def index():
content = ""
error = None
if request.method == 'POST':
domain = request.form.get('domain')
if domain:
content = safeURLOpener(domain)
return render_template('index.html', content=content, error=error)
if name == '__main__':
app.run(debug=True)- Index.html
<!DOCTYPE html>
<html>
<head>
<title>Domain Content Viewer</title>
</head>
<body>
<h1>Domain Content Viewer</h1>
<form method="post">
<label for="domain">Enter a domain:</label>
<input type="text" name="domain" id="domain" value="{{ request.form['domain'] }}">
<button type="submit">Submit</button>
</form>
{% if content %}
<h2>Content:</h2>
<pre>{{ content }}</pre>
{% endif %}
{% if error %}
<h2>Error:</h2>
<p>{{ error }}</p>
{% endif %}
</body>
</html>run the app using python3

which running by default to 127.0.0.1:5000
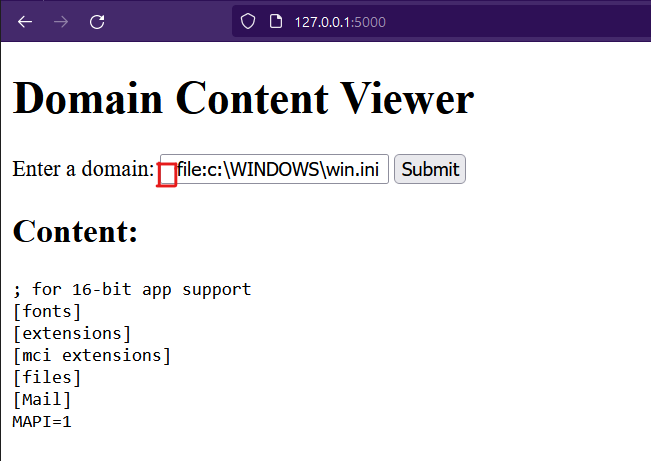
in case submitting a common payload of LFI file:c:\WINDOWS\win.ini Windows-based

the application returned with Input schema is forbidden because file schema blocked by the blocklist
After adding a space in the URL, the application blocklisting failed to detect the URL schema and causes bypassing of the
blocklist
Setting the Debugging Environment
the vulnerable library: https://github.com/python/cpython/tree/3.11/Lib/urllib
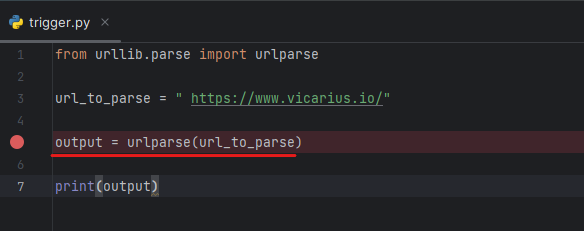
from urllib.parse import urlparse
url_to_parse = " https://www.vicarius.io/"
output = urlparse(url_to_parse)
print(output)then add the breakpoint in the line that uses the function to trigger the vulnerable function
start the debugger by clicking on the debugger button in the tools bar

After running the debugger and stepping into it to let the IDE go to the source code of the installed Python version in the
machine, the default in Windows is C:\Users\yosef\AppData\Local\Programs\Python\Python39\Lib\urllib.
It appears that it calls the urlparse function, which exists in the parse.py file.
urlparse
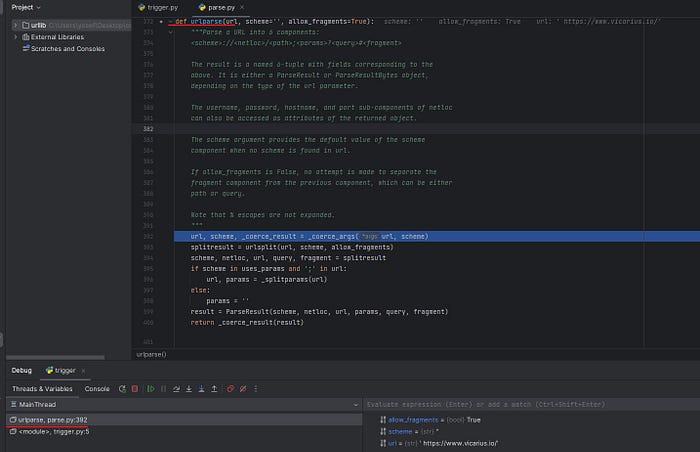
urlparse function first breaks down the provided argument into two pieces
the scheme and
URl set it to an empty string (scheme='') as the default and the given
URL. The function then proceeds to parse the argument
by passing it to the _coerce_args function
_coerce_args
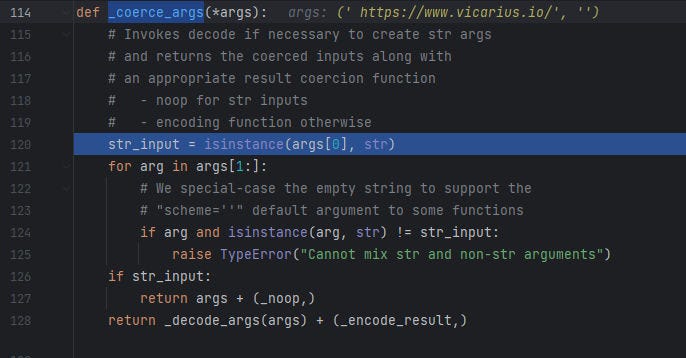
_coerce_args function make sure the given argument if it was a string
return noop and if not raise an error Cannot nix str and non-str arguments
then urlparse call urlspilt to spilt the given url into scheme, netloc
(network location), url, query, and fragment.
urlsplilt
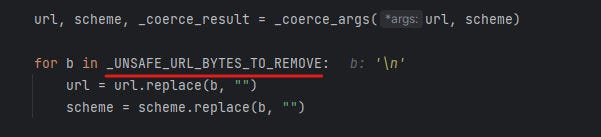
urlsplilt have all the important works, which use
UNSAFE_URL_BYTES_TO_REMOVE variable as shown below to remove '\t', '\r', '\n' prevent injection

Root Cause
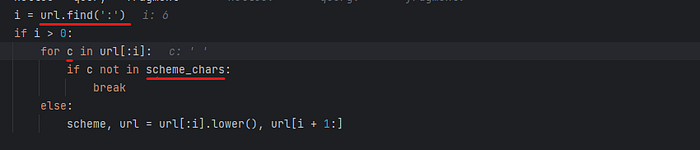
for c in url[:i] which checks for the characters in the URL first part before the colon (file schema) using url.find(':') for
all characters if c among the valid characters that exist in scheme_chars variable as shown below:

if c characters existed in scheme_chars the code will proceed and save it as the scheme component and when and the root cause of this CVE when the code fails to get the the schema the code processing without getting the schema as shown in the stack tracing below:
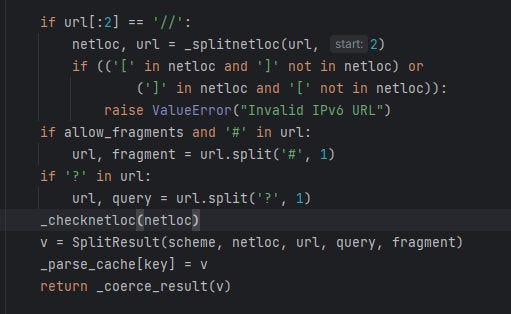
and then checks for the netloc which starts in line number 380 in the code checking the part before // and checks if []
not exist in IPv6 URL format rise an error says Invalid IPv6 URL then it checks for the fragments (sections indicated by #)
and then the query and pass the netloc to _checknetloc() function
and for _checknetloc(netloc)

The _checknetloc() function handles the network location by first confirming whether it consists of ASCII characters or not. It then proceeds to replace symbols like '@', ':', '#', and '?' and normalizes the resulting string. Afterward, the function checks if these characters still exist; if they do, an error is raised
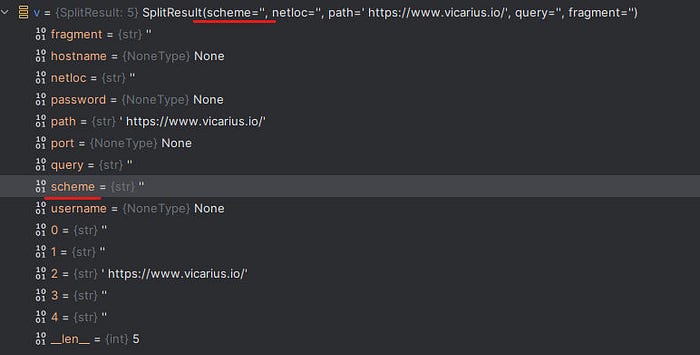
and then it saves the into variable parseResult which appears below picture of the code processed without getting the
schema and netloc components and save the URL into path
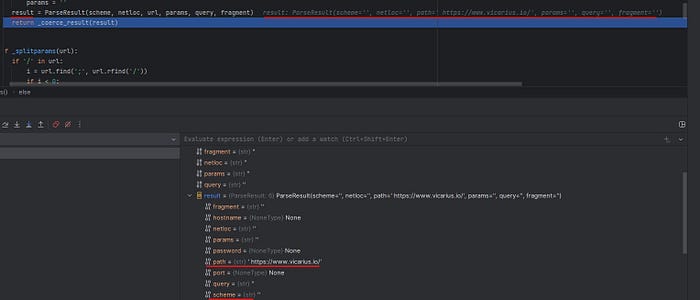
Patch diffing
link: https://github.com/python/cpython/pull/99421/commits/a284d69de1d1a42714576d4a9562145a94e62127
the modification of the library was by adding

test_attributes_bad_scheme function which checks by looping a range of possible invalid
scenarios schemes, including ".", "+", "-", "0", "http&" and non-ascii to prevent the bypassing using a blank as the previous
exploitation
Mitigation
Upgrade Python to the lasted version 3.11.4
Final Thoughts
after diving deep into the source code of the Python library urllib and debugging the library we take a look can simple bugs
do a significant impact as we see simple plank can bypass any blacklisting
Reference:

Join vsociety: https://vsociety.io/
Checkout our discord: https://discord.gg/sHJtMteYHQ
